Il cane che non abbaiava nella notte: il pericolo del superstite Bias in AI
L’Intelligenza Artificiale è ancora (un po ‘) una parola d’ordine, anche se in pratica gran parte di ciò che è probabile che venga implementato in questo attuale ciclo economico sotto quell’ombrello onnicomprensivo è stato. Sistemi di riconoscimento visivo, controllo. Riconoscimento vocale, controllo. Sistemi esperti, verifica. Veicoli a guida autonoma, controllare. Motori di raccomandazione, sì. Strumenti di Business Intelligence con un’infarinatura salutare della scienza dei dati, controllo, controllo, controllo. Nessuno di questi è ancora abbastanza perfetto (e probabilmente alcuni sono un modo lungo per raggiungere anche un’applicabilità pratica), ma la forma del futuro immediato, diciamo nei prossimi cinque anni circa, è abbastanza chiara.
Capire pregiudizi Survivor
Finora, la maggior parte del software sta appena iniziando a entrare nell’era dell’intelligenza artificiale specializzata (SAI). Una buona definizione operativa per SAI è che si tratta di un software in cui la logica è determinata non da un programmatore, ma dall’analisi dei dati da parte di un particolare processo e dalla distribuzione di un modello derivato da tale analisi. In altre parole, diciamo che hai un’applicazione che scatta una fotografia di una persona contro una scala conosciuta e usa determinate regole predefinite per determinare se quella persona è maschio o femmina, come altezza, distribuzione del peso, lunghezza dei capelli, la presenza o l’assenza di determinati vestiti o articoli e così via.
Un approccio algoritmico a questo problema è creare bucket che identificano dimensioni specifiche o tratti qualificanti, quindi determinare se una determinata persona cade in una particolare configurazione di bucket. Questa non è, da sola, l’intelligenza artificiale, sebbene sia la base per un gran numero di sistemi esperti.
Tuttavia, diciamo che un essere umano crea un set di dati che contiene gli stessi bucket (o faccette), quindi utilizza un algoritmo di apprendimento automatico per confrontare altri individui con questo set di base, producendo misure statistiche di idoneità. Il modello che è stato creato ora non dipende più dall’input diretto di un programmatore (sebbene l’input indiretto sia una domanda diversa), ma piuttosto è diventato un algoritmo determinato dall’idoneità statistica basata sui dati di origine. La conferma di tale adattamento può quindi andare a perfezionare il modello, creando una struttura adattabile che converga meglio sulla distribuzione “effettiva” dei tratti.
Questo approccio statistico (noto anche come stocastico) è un segno distintivo dell’IA. Un modello viene creato in base ai dati, l’uso predittivo di quel modello sui nuovi dati aiuta a perfezionare il modello, a risciacquare e ripetere. Almeno questa è la teoria. In pratica, la maggior parte delle aree dei sistemi SAI dipende in gran parte dall’avere dati di buona qualità, imparziali , qualcosa che è, di fatto, in un’offerta estremamente breve. I sondaggisti professionisti, che probabilmente stanno lavorando per un po ‘all’intelligenza artificiale ora, vi diranno quanto sia difficile mantenere il pregiudizio nel loro lavoro.
Un semplice esempio di pregiudizio può essere visto nei sondaggi politici. La stragrande maggioranza dei sondaggi fino a quando di recente ha utilizzato sondaggi telefonici per determinare dove un particolare candidato si trovava con l’elettorato. Prima del 2008, questo non era un grosso problema: la maggior parte delle persone aveva linee di terra e i telefoni cellulari venivano trovati solo nelle mani di una minoranza molto piccola e generalmente elitaria.
Quella situazione è cambiata radicalmente nel corso del prossimo decennio, nella misura in cui le linee di terra sono ormai in via di estinzione. Eppure ci è voluto un po ‘perché i sondaggisti se ne rendessero conto, con il risultato che, come misurato dai loro dati di origine, l’elettorato stava diventando molto più vecchio e più conservatore, semplicemente perché quelle erano le persone meno probabilità di passare ai telefoni cellulari . Aggiungete a questo le sempre più precise capacità di intelligenza artificiale dei telefoni cellulari stessi per determinare se una determinata chiamata fosse una chiamata spam (e molte persone considerano tali sondaggi come spam), e questo ha distorto ancora di più il pregiudizio.
Abbattere aerei
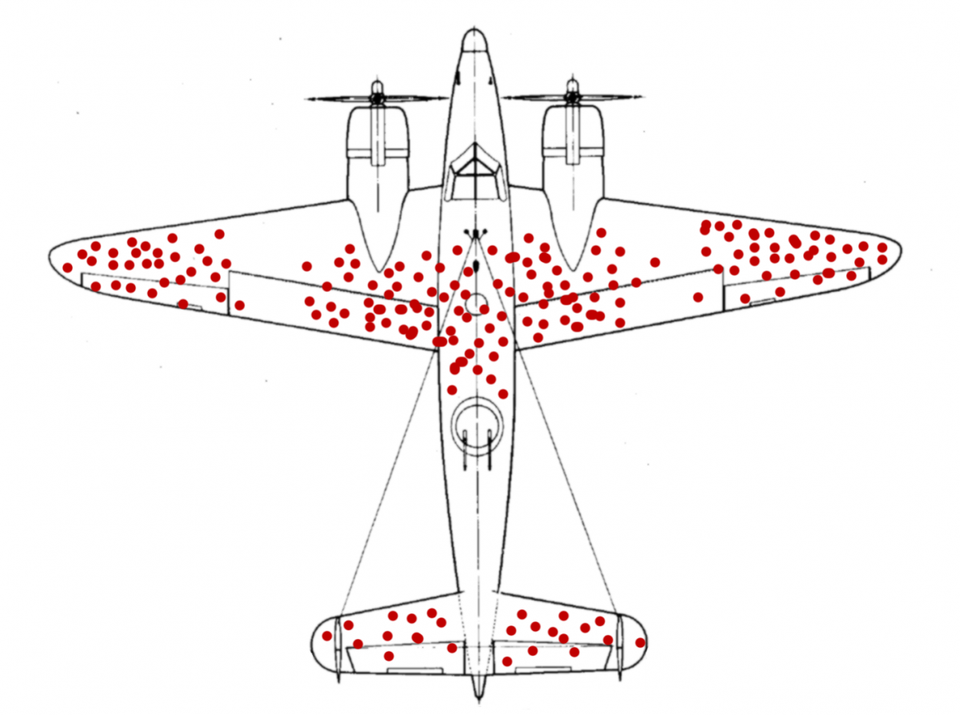
Questo è un esempio di parzialità del sopravvissuto e mostra come, anche quando vengono fatti tentativi per cercare dati solidi, è possibile che tali metodi stocastici creino modelli errati – e da lì, una cattiva politica quando questi modelli vengono implementati come decisori. Il nome deriva in realtà da un’analisi condotta dallo statistico Abraham Wald durante la seconda guerra mondiale . Wald esaminò un rapporto fatto dalla Marina che illustrava i fori dei proiettili negli aerei che tornavano dalle missioni.
Il rapporto iniziale formulava la raccomandazione di mettere un’armatura (costosa sia da installare che da pilotare) su quelle aree, ma Wald riuscì a fare la contro-argomentazione: quegli aerei l’avevano fatta tornare a casa nonostante i danni subiti in quei luoghi, il che suggeriva fortemente che gli aerei che aveva subito danni altrove non erano in grado di tornare indietro. La sua raccomandazione era di armare quelle parti di bombardieri che sembravano relativamente incontaminate, e il suggerimento, una volta attuato, ha visto un significativo miglioramento nei tassi di sopravvivenza delle sortite.
Questo pregiudizio sopravvissuto, sfortunatamente, si verifica ovunque e può essere particolarmente pernicioso quando si tratta di modelli che hanno un numero di variabili differenti. Ad esempio, il software di intelligenza artificiale che formula raccomandazioni di approvazione per i prestiti immobiliari è basato su record storici di credito. Tuttavia, un buon credito è spesso determinato come una funzione di avere un flusso di denaro solido e regolare. Se storicamente i prestiti non sono stati concessi a minoranze (sono stati abbattuti in modo figurato) a causa di pregiudizi razziali o fattori simili, il software che utilizza tali dati storici non avrà altrettanti casi di proprietari di case di minoranza. In quanto tale, il software sarà prevenuto in modo preventivo per negare il credito, anche se un determinato acquirente ha altrimenti un credito eccellente.
È, infatti, questo particolare enigma che affronta i motori di raccomandazione, che sono in genere IA di apprendimento automatico. Quando selezioni un video su Netflix o un eBook su Amazon, questo ti identifica come interessato a uno specifico set di bucket e il motore dei consigli trova quindi il contenuto più vicino a quella configurazione che può. Se il tuo mezzo preferito sono i romanzi polizieschi paranormali, dopo un po ‘, tutto ciò che vedi è una variante di un romanzo poliziesco paranormale. Sono i sopravvissuti. Tuttavia, dopo un po ‘, potresti stancarti di questo particolare genere e provare qualcosa nel genere thriller, ma la tua impressione sul negozio è che non ci sono buoni romanzi thriller semplicemente perché non sono sopravvissuti.
Questa è una ragione per cui tali raccomandazioni sono sempre più adattive, spesso incorporando valori anomali in una ricerca per ravvivare un po ‘il mix. In altre parole, un buon sistema di apprendimento automatico ha bisogno di un modo sistematico per dimenticare le informazioni che sono obsolete.
Oltre a ciò, tali sistemi di apprendimento automatico sono sempre più in grado di rilevare i modelli emergenti in anticipo. Questo è particolarmente importante per il caching. L’apprendimento automatico, la costruzione di un modello al volo con i dati in arrivo, è un’operazione relativamente costosa. Anziché eseguire un simile confronto ogni volta che qualcuno fa una raccomandazione (che potrebbe mettere in ginocchio Netflix o Amazon) la maggior parte dei motori di raccomandazione analizza i dati, crea il modello, quindi memorizza il modello in una sorta di sistema indicizzato come un database relazionale , negozio triplo o negozio NoSQL. Le cache di solito scadono per un certo periodo di tempo, ma alcuni tipi di query possono far scattare un cavo rigido che indica al sistema che il contenuto preconosciuto potrebbe essere stantio e deve essere ricalcolato.
Il cane che non abbaiava nella notte
Questa capacità di rilevare e proprietà interpretare anti-modelli sta diventando una delle aree più calde della ricerca di intelligenza artificiale. I fan di Sherlock Holmes sono probabilmente a conoscenza del “cane che non abbaiava durante la notte” quando un cavallo da corsa pregiato scomparso. Lo schema era che il cane abbaiava quando gli estranei si avvicinavano, l’anti-modello era che il cane non abbaiava durante il furto, il che a sua volta portava Holmes a rendersi conto che il cane in questione conosceva bene il ladro.
Ancora una volta, si tratta di una riformulazione del pregiudizio dei sopravvissuti, ed è notevolmente difficile da incorporare proprio perché gli antipattern sono emergenti, inaspettati e spesso segnalati solo dall’assenza di informazioni.
Ciò non significa che l’apprendimento automatico non valga nulla, anzi, anzi. L’apprendimento automatico è uno strumento molto potente per fare la categorizzazione iniziale. Inoltre, può anche “dare il via” a quei casi particolari che non si adattano facilmente ai modelli esistenti, il che significa che possono essere trattati come valori anomali e analizzati su tale base. I valori anomali sono sempre stati problematici, potrebbero rappresentare un rumore statistico, ma potrebbero anche essere indicativi delle tendenze emergenti.
Tuttavia, prima che l’IA specialistica entri troppo profondamente in vari cicli decisionali, vale la pena (l’analisi umana) per determinare se i dati di addestramento sono stati adeguatamente rappresentativi e completi e, data l’indicazione di ciò, è probabile che tale distorsione sia presente. Senza quel pezzo critico di governo umano, a seconda del linguaggio macchina, l’IA è avventata nel migliore dei casi e pericolosa nel peggiore dei casi.
Sommario
L’Intelligenza Artificiale Specializzata, specialmente come evidente nei sistemi Machine Learning e Deep Learning, rappresenta un cambiamento qualitativo nel modo in cui usiamo i sistemi software. Ci stiamo allontanando dall’idea che la logica del computer sia creata direttamente dai programmatori umani, spostandoci invece verso la nozione che i sistemi informatici stanno sempre più ricavando le proprie conoscenze attraverso il processo continuo di modellizzazione e categorizzazione sistemica basata su flussi di dati.
Tuttavia, poiché questa forma di programmazione diventa più pervasiva, dovremmo essere diligenti nel riconoscere che la parzialità, specialmente quella dei sopravvissuti, può distorcere le nostre aspettative e darci falsi modelli che a loro volta possono escludere o ferire le persone che non sono nemmeno consapevoli del loro uso . Il pericolo che questo introduce è sotto molti aspetti molto più profondo e insidioso della minaccia dell’automazione sull’occupazione, soprattutto perché è così sottile e invisibile.